
Adding Fixed point arithmetic to your design

This article is a part of a series where we implement an FPGA based Convolutional Neural Network accelerator. However, the content of this article is useful for understanding the 'Fixed-point' number representation and using it in any hardware design. You can understand the general principle and use the code even if you aren't interested in the entire series of articles.Now you can access an FPGA LAB environment on demand with chiprentals. This service is currently in the Beta stage and is being provided for free. Go perform your projects in a real world environment. Book your slot here. The PYNQ-Z2 board being offered currently is the best choice for trying out ML and AI acceleration projects like this one.
Part One - The Architecture Outline
Part Two - The Convolution Engine
Part Three - The Activation Function
Part Five - Adding fixed-point arithmetic to your design
Part Six - Generating data and automating the Verification Process
Part Seven - Creating a multi-layer neural network in hardware.
Why do we need a number representation system?
To be able to apply our hardware on real life inputs and data, we need it to be able to interpret the various formats humans use to interpret this data. Real world data has everything from sign (positive or negative) to fractional values and integral values. However, when we work with hardware, all we see is registers and wires which are simply variables capable of holding a sequence of bits. All we get to choose is the length of this sequence. There is simply no other parameter involved in defining these variables. As the author of this excellently written whitepaper on fixed point arithmetic puts it
"The salient point is that there is no meaning inherent in a binary word, although most people are tempted to think of them (at first glance, anyway) as positive integers. However, the meaning of an N-bit binary word depends entirely on its interpretation, i.e., on the representation set and the mapping we choose to use."
The terms Fixed-point and Floating-point are simply that, they're representation sets and mapping schemes that have been widely used and standardized by the entire community. You could totally choose to come up with your own new representation and use it to interpret these binary words.
There's probably enough material out in the open that can teach you about the basics of representing numbers on computers and the differences between fixed-point and floating-point numbers.
The hardware itself has no concept of fixed-point of floating-point numbers. It just recognizes fields with certain bit widths. This means that we need a layer above the hardware to help us generate numbers in the chosen format with chosen precision and at the same time help us interpret the results that the hardware is giving us by converting the raw binary words into the chosen format.
We implement this upper layer using python mainly because of its simplicity and code readability.
The Format
Fixed-point numbers are those in which the position of the decimal point remains fixed independent of the value that number is representing. This is what makes fixed point numbers easier to understand as well as implement in hardware in comparison to the floating point numbers. Fixed point arithmetic also uses much less resources in comparison to floating point arithmetic. Of course all of this comes at a tradeoff. Floating point arithmetic can provide higher levels of precision for a particular bit-width than fixed-point arithmetic. We take a hit in terms of the quantization noise when we use numbers in which the binary point in a fixed position despite the magnitude being represented by that number.
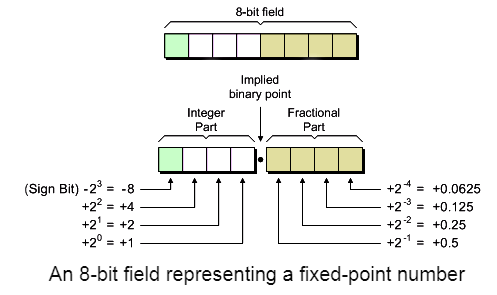
We shall be using a Signed 2's complement fixed-point representation wherein, as show in in the above image, the first bit represents the sign bit and if the number is negative (sign bit = 1) it is assumed that it is in a 2's complement form. We need to be mindful of this when dealing with negative numbers.
There are several notations to properly denote the various parameters of a fixed point number. The most popular one is probably the A(a,b) format wherein a is the number of bits used to represent the integer portion of the number and b is the number of bits used to represent the fractional portion of the number. Which means that the total number of bits used to store an A(a,b) fixed point number is N = a + b + 1.
The values of a,b are to be selected based on the range and precision that you need for the problem at hand. For example, if all or most of the numbers you're trying to represent have a very small magnitude, you might forgo range for more precision i.e you can use less bits to represent the integral portion and use more bits to represent the fractional portion thus achieving greater precision in your arithmetic. This is a decision that you need to make on the basis of the exact application where your hardware will be used.
If you need a further detailing on fixed-point numbers, go through this document.
The Golden Model
Before we move on to implement the fixed point arithmetic in Verilog, let's create a golden model i.e a model of the target functionality that gives use the correct target outputs which we can use to check the results from the actual Verilog implementation and fix any bugs based on the wrong outputs.
We define a few functions that allow us to convert numbers between the standard floating-point representation that python uses and the fixed point representation that we want our hardware to use and vice-versa.
Below is the code for a function that converts a number in the standard float format to a user specified format. The variable integer_precision represents the number of bits to be used to represent the integer part (before the decimal point) of the fixed point number and the variable fraction_precision denotes the number of bits used for the fractional part (after the decimal point).
NOTE: When I mention a float variable hereon after, it represents the 'float' data type in python. Apparently, it is stored in the form of a 32-bit floating point number by the CPU under the hood
def float_to_fp(num,integer_precision,fraction_precision):
if(num<0):
sign_bit = 1 #sign bit is 1 for negative numbers in 2's complement representation
num = -1*num
else:
sign_bit = 0
precision = '0'+ str(integer_precision) + 'b'
integral_part = format(int(num),precision)
fractional_part_f = num - int(num)
fractional_part = []
for i in range(fraction_precision):
d = fractional_part_f*2
fractional_part_f = d -int(d)
fractional_part.append(int(d))
fraction_string = ''.join(str(e) for e in fractional_part)
if(sign_bit == 1):
binary = str(sign_bit) + twos_comp(integral_part + fraction_string,integer_precision,fraction_precision)
else:
binary = str(sign_bit) + integral_part+fraction_string
return str(binary)the 'twos_comp' function being used by this code is another function that we use to generate the 2's compliment of any binary number. Here is the code:
def twos_comp(val,integer_precision,fraction_precision):
flipped = ''.join(str(1-int(x))for x in val)
length = '0' + str(integer_precision+fraction_precision) + 'b'
bin_literal = format((int(flipped,2)+1),length)
return bin_literalLet's run these function and see what we've built:
#TWO'S COMPLEMENT
print(twos_comp('0110011110110110', 3, 12))
-> 1001100001001010
#CONVERTING A POSITIVE FLOAT NUMBER TO FIXED-POINT
print(float_to_fp(2.356,3,12))
-> 0010010110110010
#CONVERTING A NEGATIVE FLOAT NUMBER TO FIXED-POINT
print(float_to_fp(-2.356,3,12))
-> 1101101001001110And finally a function to convert data from our fixed-point representation to a human readable float variable:
def fp_to_float(s,integer_precision,fraction_precision): #s = input binary string
number = 0.0
i = integer_precision - 1
j = 0
if(s[0] == '1'):
s_complemented = twos_comp((s[1:]),integer_precision,fraction_precision)
else:
s_complemented = s[1:]
while(j != integer_precision + fraction_precision -1):
number += int(s_complemented[j])*(2**i)
i -= 1
j += 1
if(s[0] == '1'):
return (-1)*number
else:
return numberLet's see how well this function is working:
print(fp_to_float('1101101001001110',3,12))
-> -2.35595703125
print(fp_to_float('0010110111111011',3,12))
-> 2.87353515625Finally, just for our heart's satisfaction, let's see what happens when we nest these functions together!
print(fp_to_float(float_to_fp(-2.729,3,12),3,12))
-> -2.728515625WHOA! What just happened here? How come the value is different when converted back and forth between fixed-point and float representation?
That my friends is the lack of precision of the fixed-point representation in action. When we store a float variable in python, the CPU actually stores it in a 32-bit floating point number in its memory, when we change that to a 16 bit fixed point representation, we loose a teeny tiny bit of precision as the fixed-point representation does not have enough bits to achieve the same precision as the 32-bit floating point variables.
Designing hardware for fixed-point arithmetic
Now that we have a solid Golden model ready, let's begin coding in Verilog!
The following code snippets are modified versions of the fixed-point arithmetic library from Opencores.
Fixed-point Addition
//file: qadd.v
`timescale 1ns / 1ps
module qadd #(
parameter Q = 15,
parameter N = 32
)
(
input [N-1:0] a,
input [N-1:0] b,
output [N-1:0] c
);
// (Q,N) = (12,16) => 1 sign-bit + 3 integer-bits + 12 fractional-bits = 16 total-bits
// |S|III|FFFFFFFFFFFF|
// The same thing in A(I,F) format would be A(3,12)
//Since we supply every negative number in it's 2's complement form by default, all we
//need to do is add these two numbers together (note that to subtract a binary number
//is the same as to add its two's complement)
assign c = a + b;
//If for whatever reason your system (the software/testbench feeding this hadrware with
//inputs) does not supply negative numbers in their 2's complement form,(some people
//prefer to keep the magnitude as it is and make the sign bit '1' to represent negatives)
// then you should take a look at the fixed point arithmetic modules at opencores linked
//above this code.
endmoduleFixed-point Multiplication
//file: qmult.v
`timescale 1ns / 1ps
// (Q,N) = (12,16) => 1 sign-bit + 3 integer-bits + 12 fractional-bits = 16 total-bits
// |S|III|FFFFFFFFFFFF|
// The same thing in A(I,F) format would be A(3,12)
module qmult #(
//Parameterized values
parameter Q = 12,
parameter N = 16
)
(
input [N-1:0] a,
input [N-1:0] b,
output [N-1:0] q_result, //output quantized to same number of bits as the input
output overflow //signal to indicate output greater than the range of our format
);
// The underlying assumption, here, is that both fixed-point values are of the same length (N,Q)
// Because of this, the results will be of length N+N = 2N bits
// This also simplifies the hand-back of results, as the binimal point
// will always be in the same location
wire [2*N-1:0] f_result; // Multiplication by 2 values of N bits requires a
// register that is N+N = 2N deep
wire [N-1:0] multiplicand;
wire [N-1:0] multiplier;
wire [N-1:0] a_2cmp, b_2cmp;
wire [N-2:0] quantized_result,quantized_result_2cmp;
assign a_2cmp = {a[N-1],{(N-1){1'b1}} - a[N-2:0]+ 1'b1}; //2's complement of a
assign b_2cmp = {b[N-1],{(N-1){1'b1}} - b[N-2:0]+ 1'b1}; //2's complement of b
assign multiplicand = (a[N-1]) ? a_2cmp : a;
assign multiplier = (b[N-1]) ? b_2cmp : b;
assign q_result[N-1] = a[N-1]^b[N-1]; //Sign bit of output would be XOR or input sign bits
assign f_result = multiplicand[N-2:0] * multiplier[N-2:0]; //We remove the sign bit for multiplication
assign quantized_result = f_result[N-2+Q:Q]; //Quantization of output to required number of bits
assign quantized_result_2cmp = {(N-1){1'b1}} - quantized_result[N-2:0] + 1'b1; //2's complement of quantized_result
assign q_result[N-2:0] = (q_result[N-1]) ? quantized_result_2cmp : quantized_result; //If the result is negative, we return a 2's complement representation
//of the output value
assign overflow = (f_result[2*N-2:N-1+Q] > 0) ? 1'b1 : 1'b0;
endmoduleWait a second, it takes 2*N bits to hold the result of the multiplication between two N - bit numbers right? Right.
Then Why is our outpur the same width as the multiploer and multiplicand?
This is because of the quantization that needs to be done at some point in the process in order to preserve the width of our data-path. If we keep increasing the size of the output at every multiplication that we encounter, we will end up with an insanely large datapath. This quantization adds something called the quantization-noise to our data since we're truncating the 2*N bit output to N bits. We should keep it in mind not to overflow and loose too much information in the truncation process. This is true most of the time if the numbers are pretty small and within the dynamic range of the fixed-point representation.
All the design files along with their test benches can be found at the Github Repo