
FPGA based acceleration of machine learning algorithms involving convolutional neural networks

Photo by Markus Spiske on Unsplash
This series of articles goes into great detail in the process of implementing a convolutional neural network on an FPGA. If you already have a good idea of Machine Learning and Convolutional Neural Networks in general and have an appreciation for the problem at hand, you can jump to the next article in the series where the planned architecture is outlined. But if you are like me, and you love to indulge in some discussion about how amazing this technology is and where it is taking us as humans, read on and tell others what you think in the comments...Now you can access an FPGA LAB environment on demand with chiprentals. This service is currently in the Beta stage and is being provided for free. Go perform your projects in a real world environment. Book your slot here. The PYNQ-Z2 board being offered currently is the best choice for trying out ML and AI acceleration projects like this one.
Part Zero - The Introduction
Part One - The Architecture Outline
Part Two - The Convolution Engine
Part Three - The Activation Function
Part Five - Adding fixed-point arithmetic to our design
Part Six - Generating data and automating the Verification Process
Part Seven - Creating a multi-layer neural network in hardware.
The Machine Learning Problem
Unless you have been living under a rock (or in North Korea?), you already know that Machine Learning has taken over the tech world. There are innumerable people and tech companies out there today trying to throw this idea of Machine Learning at every problem they haven't been able to figure out a solution to. You probably also know that the most promising subfield of machine learning that has shown tremendous promise in everything from object detection to autonomous driving is that of Deep Learning.
Deep learning, which broadly consists of applications involving certain specialized structures called Neural Networks has given the biggest boost to the entire area of machine learning and Artificial Intelligence research. They have exhibited tremendous abilities in doing tasks that were traditionally very hard for computers to do, to the extent that some deep learning approaches have been shown to perform even better than humans at some tasks like vision and speech recognition.
Given this immense potential and the race to capitalize on it, there has been a huge interest in accelerating the inference of neural networks especially by the big internet companies with tools ranging from voice assistants to autonomous navigation that handle loads of real-time user data that needs to be run through huge neural networks and the result needs to be served to the user within milliseconds.
The software part of accelerating these immense workloads of data has saturated quite a bit ago and we have a variety of deep learning frameworks that successfully squeeze out the last bit of efficiency on the software end. So people now are turning to ideas that include creating specialized hardware that does only one thing, runs inputs through neural network architectures, and produce outputs, but does it extremely well and extremely fast.
Now to understand what kind of specialized hardware we are looking for, we need to look at the stages in the lifecycle of a neural network, or any machine learning algorithm for that matter. This life-cycle can be broadly said to have two parts, training and inference.
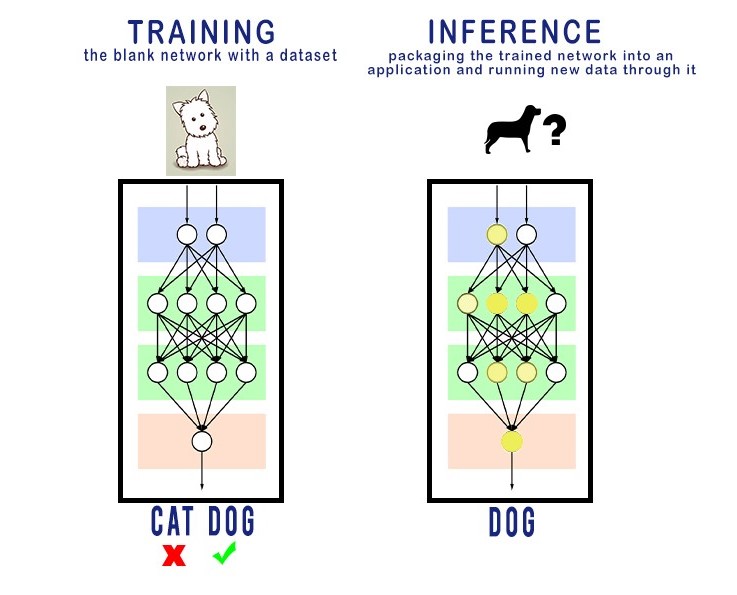
Training: This is the stage where the parameters in the machine learning algorithm are trained (modified) in a way that enables them to detect the required patterns in the input data by repeatedly exposing them to sample inputs and sample inputs. This is only the case for supervised learning, there are many other ways to train a neural network and there are enough great blogs on the internet to teach you that.
Inference: Inferencing is the process of passing inputs to an already trained neural network and extracting useful outputs on the other side. Weights and parameters in the algorithm are frozen for this step. They are no longer being modified. Another simple term for inference would be deployment, i.e after being trained to the required performance, the algorithm is being deployed via an app or a service to serve people by doing its job. This is exactly what happens when you ask Siri or Alexa a question, they send your voice data to a data center that runs your voice command through a machine learning algorithm that has been trained to recognize patterns in your voice.
It is quite obvious that training is a much more computationally intensive job in comparison to inference. But here is the key, training is a one time job. That's not to say that there is no real incentive in developing tech to train neural networks faster, but the point is inferencing is the process that is run over and over again until the end of time (yeah hehe) and an average user isn't going to wait 5 minutes for Siri to respond to 'how is the weather today?'. So there has been a lot of time and money invested into the research for groundbreaking solutions that make inferences run faster and faster with near-zero latency between input and output. So our design is going to be targeted towards accelerating the inferencing process and not the training.
The Specialized Hardware
When someone talks of specialized hardware, the first thing that comes to mind is an ASIC (application-specific integrated circuit). As the name suggests, it is a circuit especially built for one purpose and it serves only that purpose. ASICs are all around us, inside your WIFI router, inside your DSLR camera and inside the satellites that orbit the planet. Some heavyweights like google and Baidu came up with their own solutions for this problem. The Google TPU is probably the most well-known project where google created an ASIC highly optimized towards accelerating inferencing of neural networks in their servers.
Except, there is a problem with ASICs, and its a big one. ASICs are insanely difficult, time taking, and capital intensive to design, test, manufacture and deploy. You literally need a huge team of people working on various stages of the ASIC design pipeline and millions of dollars invested into the process. Fabs that are capable of manufacturing these chips at scale cost gazillion dollars to build and even after all this, if you find out a tiny mistake in your design at some point in the process, you might have to start all over again (quite literally). An average ASIC takes multiple years to go from ideation to deployment.
None of this is to say that ASICs are bad, no technology in the world can give you the kind of performance for a specific problem that an ASIC can give you. But I think you can already see the problem here, the thing about the machine learning and neural network landscape is that the architectures of vastly deployed algorithms keep changing rapidly especially with respect to the number of hyper-parameters used and the layout of various layers, all of which significantly affect hardware design decisions. In fact, it has not been that long since neural networks have come into deployment in real-world products. Now compare that with something like cars or computers that have been with us for at least a century now. Of course, it would be the most efficient solution to build something that is super-optimized for a specific neural network and its architecture, but if that particular algorithm itself goes out of business in the next few months, you have just spent a gazillion dollars, months of time, thousands of human-hours into making something that's no longer state of the art.
Enter FPGAs! These motherfuckers can transform into any circuit imaginable limited only by the skill and the intent of its designer. Field Programmable Gate Arrays, as their name suggests, are field-programmable, meaning they are a general-purpose set of logic gates that can be programmed to do anything you want them to do.
Wow! so ASICs that can transform real-time! It's not as rosy as it seems though, a lot of tradeoff in performance is made when the capability to transform into a different circuit is added. Overall ASICs can be taken through stages of insane optimization for the purpose of the circuit but the same is not possible on an FPGA owing to its flexibility. These kinds of Tradeoffs, present the greatest inevitability of engineering.
So on one side, we have highly general-purpose systems like CPUs and GPUs which are capable of doing any task imaginable but are not super-efficient at the same, and on the other, we have ASICs which can run with insane levels of efficiency for the purpose at hand but take so much effort, time and money build, that they end up un-feasible for fast-moving tech. FPGAs provide a very attractive middle-ground in this tug-of-war between efficiency and generalizability. Several organizations have started investing in FPGA research in order to accelerate their servers and produce faster results for several tasks that involve machine learning. One of the well-known projects is project Brainwave at Microsoft.
Note that no FPGA hardware is required to build and understand this design, the simulator shows us enough detail about how the design is doing. However, a complete system design that implements a well known neural network in hardware with a camera on one side and a display on the other is something I plan to do as I progress through this series.
Although our design is written in Verilog and can be generalized to any process (FPGA/ASIC design), the philosophy behind such a design would be suitable for implementation on FPGAs, if you're looking for something to make an ASIC out of, you have to generalize the architecture a little bit as you won't be creating a new ASIC for every neural network out there!